Publications
Hierarchical Reinforcement Learning for Quadruped Locomotion
Submitted to IROS 2019
Legged locomotion is a challenging task for learning algorithms, especially when the task requires a diverse set of primitive behaviors. To solve these problems, we introduce a hierarchical framework to automatically decompose complex locomotion tasks. A high-level policy issues commands in a latent space and also selects for how long the low-level policy will execute the latent command. Concurrently, the low-level policy uses the latent command and only the robot's on-board sensors to control the robot's actuators. Our approach allows the high-level policy to run at a lower frequency than the low-level one. We test our framework on a path-following task for a dynamic quadruped robot and we show that steering behaviors automatically emerge in the latent command space as low-level skills are needed for this task. We then show efficient adaptation of the trained policy to a different task by transfer of the trained low-level policy. Finally, we validate the policies on a real quadruped robot. To the best of our knowledge, this is the first application of end-to-end hierarchical learning to a real robotic locomotion task.
Surveys Without Questions: A Reinforcement Learning Approach
AAAI 2019
The ‘old world’ instrument, survey, remains a tool of choice for firms to obtain ratings of satisfaction and experience that customers realize while interacting online with firms. While avenues for survey have evolved from emails and links to pop-ups while browsing, the deficiencies persist. These include - reliance on ratings of very few respondents to infer about all customers’ online interactions; failing to capture a customer’s interactions over time since the rating is a one-time snapshot; and inability to tie back customers’ ratings to specific interactions because ratings provided relate to all interactions. To overcome these deficiencies we extract proxy ratings from clickstream data, typically collected for every customer’s online interactions, by developing an approach based on Reinforcement Learning (RL). We introduce a new way to interpret values generated by the value function of RL, as proxy ratings. Our approach does not need any survey data for training. Yet, on validation against actual survey data, proxy ratings yield reasonable performance results. Additionally, we offer a new way to draw insights from values of the value function, which allow associating specific interactions to their proxy ratings. We introduce two new metrics to represent ratings - one, customer-level and the other, aggregate-level for click actions across customers. Both are defined around proportion of all pairwise, successive actions that show increase in proxy ratings. This intuitive customer-level metric enables gauging the dynamics of ratings over time and is a better predictor of purchase than customer ratings from survey. The aggregate-level metric allows pinpointing actions that help or hurt experience. In sum, proxy ratings computed unobtrusively from clickstream, for every action, for each customer, and for every session can offer interpretable and more insightful alternative to surveys.
Measurement of Users’ Experience on Online Platforms from their Behavior Logs
PAKDD 2018
Explicit measurement of experience, as mostly practiced, takes the form of satisfaction scores obtained by asking questions to users. Obtaining response from every user is not feasible, the responses are conditioned on the questions, and provide only a snapshot, while experience is a journey. Instead, we measure experience values from users’ click actions (events), thereby measuring for every user and for every event. The experience values are obtained without-asking-questions, by combining a recurrent neural network (RNN) with value elicitation from event-sequence. The platform environment is modeled using an RNN, recognizing that a user’s sequence of actions has a temporal dependence structure. We then elicit value of a user’s experience as a latent construct in this environment. We offer two methods: one based on rules crafted from consumer behavior theories, and another data-driven approach using fixed point iteration, similar to that used in model-based reinforcement learning. Evaluation and comparison with baseline show that experience values by themselves provide a good basis for predicting conversion behavior, without feature engineering.
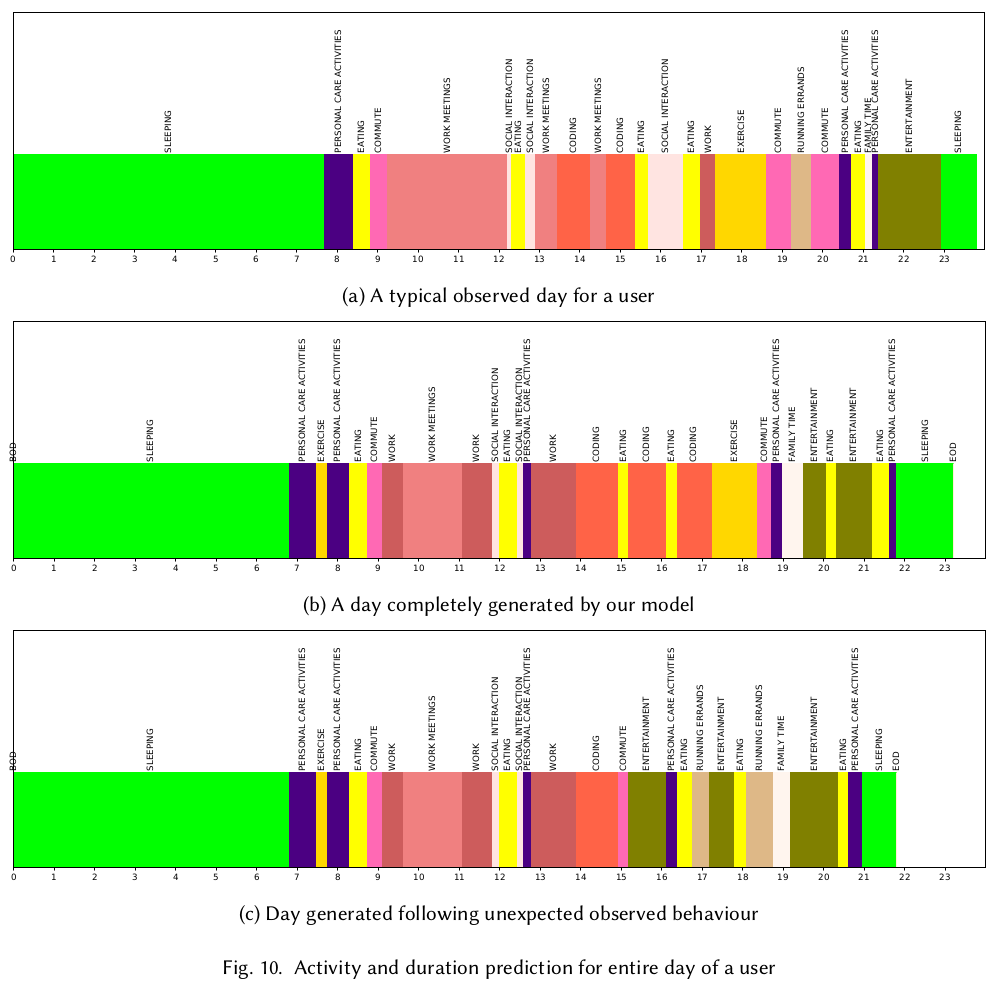
An LSTM Based System for Prediction of Human Activities with Durations
UbiComp 2018 PDF bibtex
Human activity prediction is an interesting problem with a wide variety of applications like intelligent virtual assistants, contextual marketing, etc. One formulation of this problem is jointly predicting human activities (viz. eating, commuting, etc.) with associated durations. Herein a deep learning system is proposed for this problem. Given a sequence of past activities and durations, the system estimates the probabilities for future activities and their durations. Two distinct LSTM networks are developed that cater to different assumptions about the data and achieve different modeling complexities and prediction accuracies. The networks are trained and tested with two real-world datasets, one being publicly available while the other collected from a field experiment. Modeling on the segment level public dataset mitigates the cold-start problem. Experiments indicate that compared to traditional approaches based on sequence mining or hidden Markov modeling, LSTM networks perform significantly better. The ability of LSTM networks to detect long term correlations in activity data is also demonstrated.
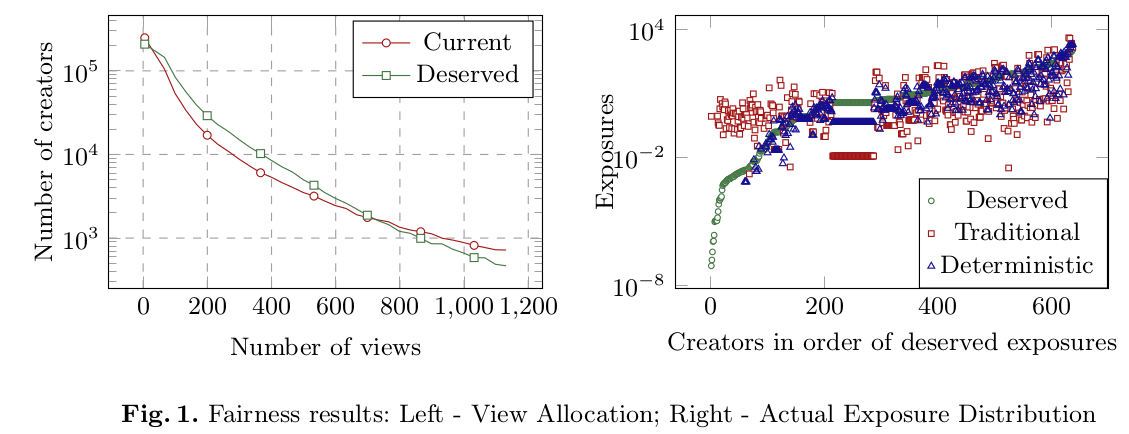
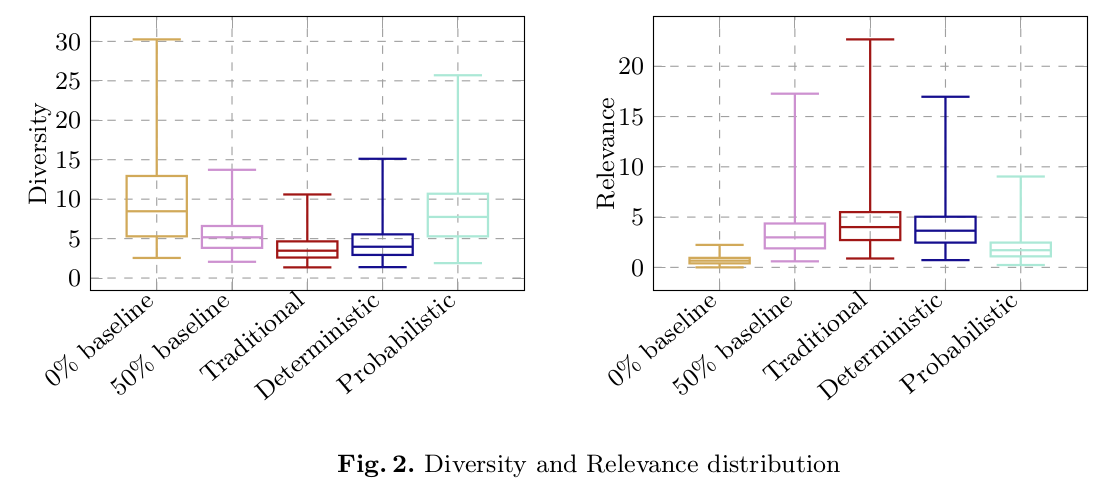
Fairness Aware Recommendations on Behance
PAKDD 2017 PDF bibtex
In two-sided platforms, the users can have two personas, consumers who would like relevant and diverse recommendations, and creators who would like to receive exposure for their creations. We propose a re-ranking strategy that can be applied to the scored recommendation lists to improve exposure distribution across the creators (thereby improving the fairness). We also propose a different notion of diversity, which we call representative diversity, as opposed to dissimilarity based diversity, that captures level of interest of the consumer in different categories. We show that our method results in recommendations that have much higher level of fairness and representative diversity compared to the state-of-art recommendation strategies, without compromising the relevance score too much.
Patent Applications
Predictive Analysis of User Behavior utilizing RNN-based User Embedding
US Patent Application 15/814,979. Filed on 17 november 2017
Creator Aware and Diverse Recommendations of Digital Content
US Patent Application 15/598,193. Filed on 16 June 2017
Personalized Creator Recommendations
US Patent Application 15/625,237. Filed on 17 May 2017